
In my opinion this is one of the most promising directions in AI. I expect significant progress in the next 5-10 years. Note the whole problem of parsing languages like English has been subsumed in the training of neural Encoders/Decoders used, e.g., in the translation problem (i.e., training on pairs of translated sentences, with an abstract thought vector as the intermediate state). See Toward a Geometry of Thought:
... the space of concepts (primitives) used in human language (or equivalently, in human thought) ... has only ~1000 dimensions, and has some qualities similar to an actual vector space. Indeed, one can speak of some primitives being closer or further from others, leading to a notion of distance, and one can also rescale a vector to increase or decrease the intensity of meaning.Geoff Hinton (from a 2015 talk at the Royal Society in London):
... we now have an automated method to extract an abstract representation of human thought from samples of ordinary language. This abstract representation will allow machines to improve dramatically in their ability to process language, dealing appropriately with semantics (i.e., meaning), which is represented geometrically.
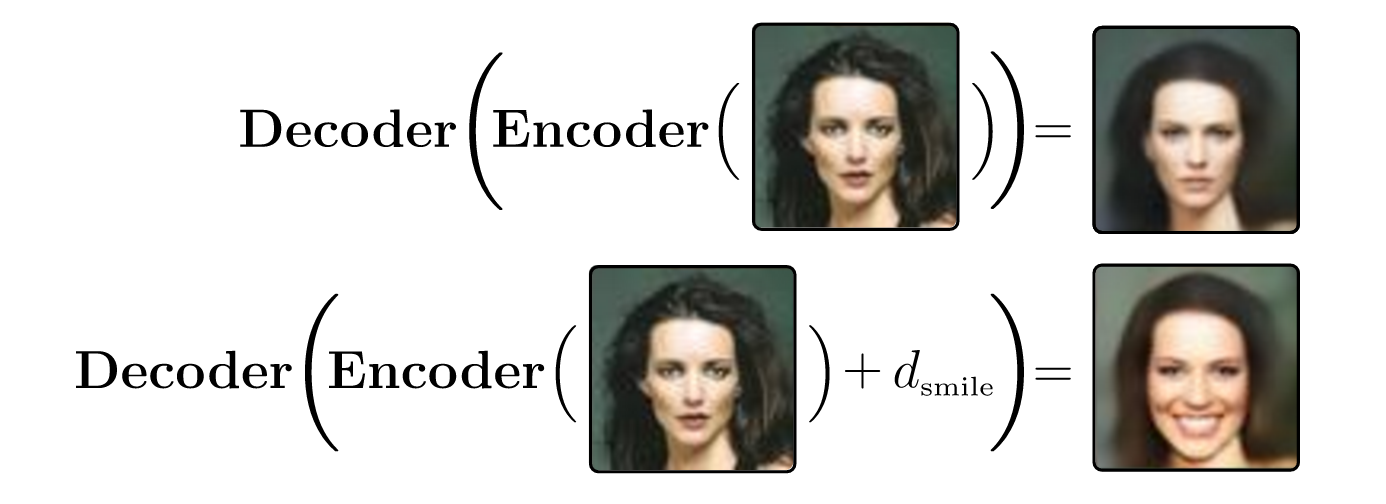
The implications of this for document processing are very important. If we convert a sentence into a vector that captures the meaning of the sentence, then Google can do much better searches; they can search based on what's being said in a document.This is a good discussion (source of the image at top and the text excerpted below), illustrating the concept of linearity in the contexts of human eigenfaces and thought vectors. See also here.
Also, if you can convert each sentence in a document into a vector, then you can take that sequence of vectors and [try to model] natural reasoning. And that was something that old fashioned AI could never do.
If we can read every English document on the web, and turn each sentence into a thought vector, you've got plenty of data for training a system that can reason like people do.
Now, you might not want it to reason like people do, but at least we can see what they would think.
What I think is going to happen over the next few years is this ability to turn sentences into thought vectors is going to rapidly change the level at which we can understand documents.
To understand it at a human level, we're probably going to need human level resources and we have trillions of connections [in our brains], but the biggest networks we have built so far only have billions of connections. So we're a few orders of magnitude off, but I'm sure the hardware people will fix that.


You can audit this Stanford class! CS224n: Natural Language Processing with Deep Learning.
More references.
No comments:
Post a Comment