
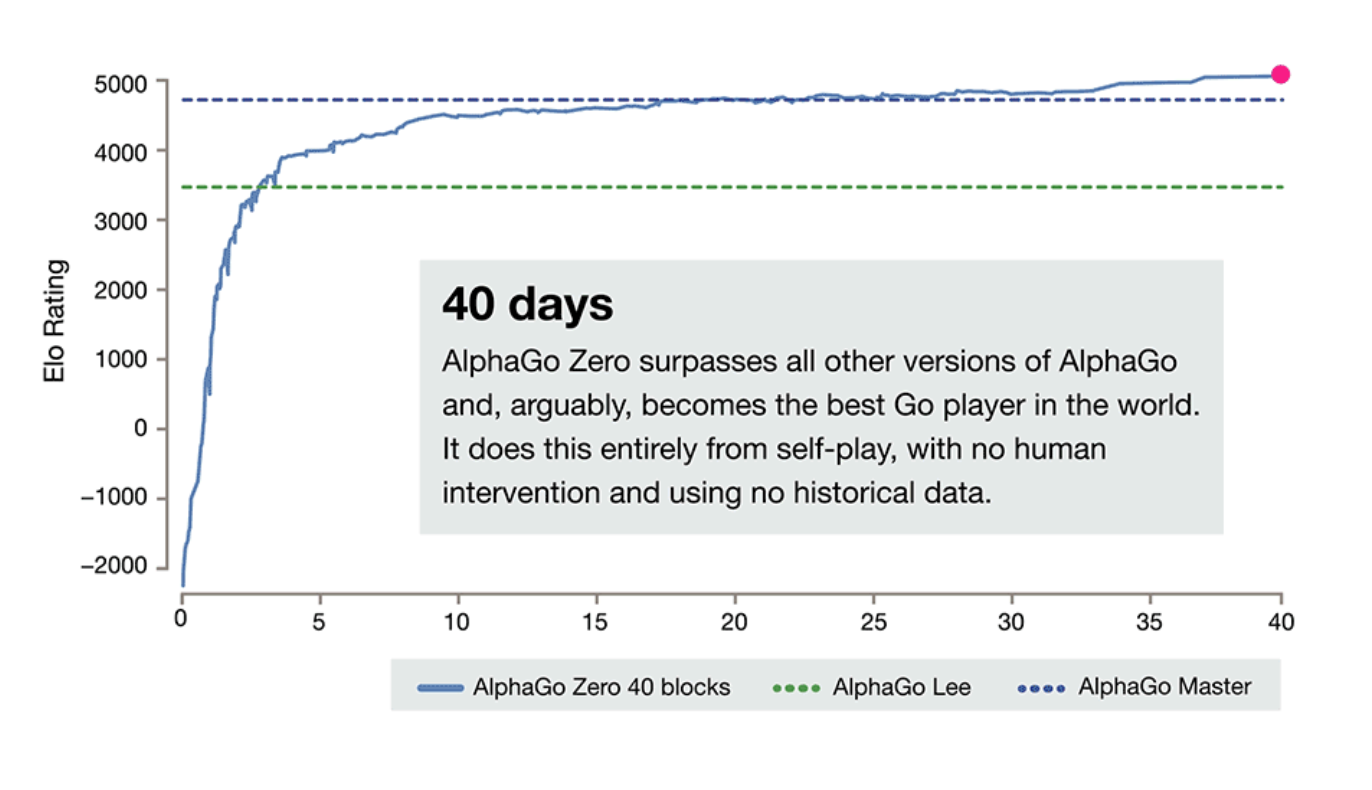
AlphaGo Zero was trained entirely through self-play -- no data from human play was used. The resulting program is the strongest Go player ever by a large margin, and is extremely efficient in its use of compute (running on only 4 TPUs).
Previous versions of AlphaGo initially trained on thousands of human amateur and professional games to learn how to play Go. AlphaGo Zero skips this step and learns to play simply by playing games against itself, starting from completely random play. In doing so, it quickly surpassed human level of play and defeated the previously published champion-defeating version of AlphaGo by 100 games to 0.Rapid progress from a random initial state is rather amazing, but perhaps something we should get used to given that:
1. Deep Neural Nets are general enough to learn almost any function (i.e., high dimensional mathematical function) no matter how complex
2. The optimization process is (close to) convex
A widely discussed AI mystery: how do human babies manage to learn (language, intuitive physics, theory of mind) so quickly and with relatively limited training data? AlphaGo Zero's impressive results are highly suggestive in this context -- the right algorithms make a huge difference.
It seems certain that great things are coming in the near future...
No comments:
Post a Comment